kees
![]()
Implementing KEES
This working draft collects a proposal for a concrete KEES implementation.
The KEES Language profile
The KEES Language Profile reuses some terms from existing, well known vocabularies:
| Prefix | URL |
|---|---|
| dct | http://purl.org/dc/terms/ |
| dqv | http://www.w3.org/ns/dqv# |
| prov | http://www.w3.org/ns/prov# |
| sd | http://www.w3.org/ns/sparql-service-description# |
| void | http://rdfs.org/ns/void# |
| xsd | http://www.w3.org/2001/XMLSchema# |
| kees | http://linkeddata.center/kees/v1# |
The Dublin Core terms, accessible at Dublin Core Terms, serve as annotations for named graphs. Specifically, properties like dct:created, dct:modified and dct:source are expected to be acknowledged in such instances.
As per the SPARQL service description vocabulary outlined in SPARQL Service Description, KEES agent are expected to acknowledge and utilize properties such as sd:endpoint, sd:feature, sd:NamedGraph, and sd:name.
Knowledge graph building activities should be traced using PROV ontology. KEES agents should recognize at least on prov:wasGeneratedBy in named graphs instances and prov:invalidatedBy in knowledge graph
The attainment of trustability is facilitated by associating quality observations with the ingested graph. To support this functionality, the KEES language profile repurposes terms from the Data on the Web Best Practices: Data Quality Vocabulary such as dqv:hasQualityAnnotation, dqv:value, and dqv:isMeasurementOf.”
When utilized in named graph metadata, a KEES agent is expected to acknowledge the term void:dataDump from the VoID Vocabulary.
The KEES vocabulary encompasses a limited set of terms defined within the http://linkeddata.center/kees/v1# namespace, commonly referenced using the prefix kees:. The whole KEES vocabulary is expressed with OWL RDF and available in kees.rdf file. A KEES agent should recognize all KEES vocabulary.
The following picture summarizes the main elements of the KEES language profile.
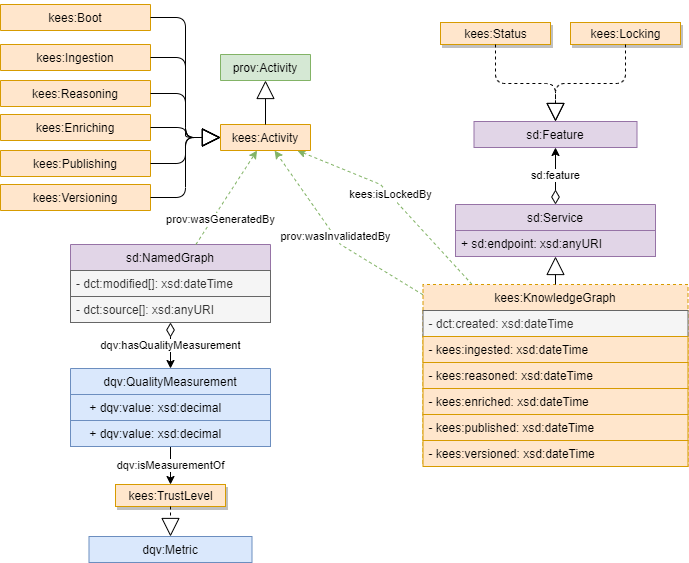
RDF Store requirement
To Know the provenance of each statement, it is of paramount importance to get an idea about data quality. For this reason, KEES requires that all statements must have a fourth element that links to a data source. This means that, for practical concerns, the KEES knowledge base is a collection of quads, i.e. a triple plus a link to metadata.
Any RDF Store that provides with a SPARQL endpoint compliant with this service description is potentially compliant with KEES.
[] a sd:Service ;
sd:supportedLanguage sd:SPARQL11Query, sd:SPARQL11Update;
sd:resultFormat <http://www.w3.org/ns/formats/RDF_XML>, <http://www.w3.org/ns/formats/Turtle> ;
sd:feature sd:UnionDefaultGraph .
KEES protocol and axioms
KEES application and agents SHOULD follow the rules in this chapter
Knowledge graph are additive
A KEES agent never delete information from knowledge graph. Temporary graph are allowed.
Knowledge Graph metadata
A KEES application should manage the following knowledge graph metadata:
prov:wasInvalidatedBywith cardinality >= 0, range prov:Activitykees:wasLockedBywith cardinality >= 0,
The boot process, should link:
sd:feature kees:Statusif the application must supports KEES window states protocolsd:feature kees:Lockingif agents must supports KEES locking protocol
Request a knowledge graph reboot
Sometime you need to signal that data in knowledge base needs (or will need) to be update. In this case you SHOULD use:
INSERT { ?service prov:invalidatedBy [ a prov:Agent ] }
WHERE { ?service a kees:KnowledgeGraph }
To test if you should reboot the knowledge base:
ASK { ?service a kees:KnowledgeGraph; prov:invalidatedBy [] }
The kees agent implementations can add restrictions on agents allowed to ask Knowledge Graph invalidation.
Booting protocol
A when requested to reboot, a KEES application should erase the entire graph store and produce a default graph equivalent to the following rule:
DROP SILENT ALL;
INSERT {
[] a kees:KnowledgeGraph ;
sd:endpoint <HERE SPARQL ENDPOINT> ;
sd:feature kees:Status, kees:Locking ;
dct:created ?now .
} WHERE { BIND( NOW() AS ?now)}
Knowledge Graph status
To check if a KEES compliant graph store is created, use:
ASK { ?service a kees:KnowledgeGraph; sd:feature kees:Status; dct:created [] }
To check if a graph store is stable, use:
ASK {
FILTER NOT EXISTS {
?activity a prov:Activity.
OPTIONAL { ?activity prov:startedAtTime ?started }
OPTIONAL { ?activity prov:endedAtTime ?endeded }
FILTER( !BOUND(?started) || !BOUND(?ended))
}
}`
### Named graph metadata
Named graph created by a KEES agent should expose following metadata:
- dct:modified with cardinality > 0, range: xsd:dateTime
- dct:source with cardinality >= 0, range: owl:Thing
- prov:wasGeneratedBy with cardinality >= 0, range: kees:Activity
To check the creation and last update date of named graphs:
```sparql
SELECT ?graphName (MIN(?updated) as ?created) (MAX(?updated) as ?lastUpdated) WHERE {
?g sd:name ?graphName ;
dct:modified ?updated
} GROUP BY ?graphName
Trust management
Trust is accomplished by annotating a named graph with the property dqv:hasQualityMeasurement with cardinality >= 0 , range a measure with dqv:isMeasurementOf kees:trustLevel attribute and dqv:value in the decimal range 0-1
Knowledge base locking
At times, multiple processes may need access to the same knowledge graph, leading to potential locking scenarios. Ideally, agents should utilize the OS standard locking mechanism (e.g., flock). However, if this isn’t feasible, a stopgap solution can be employed (though it’s not entirely secure):
To establish an exclusive lock on the knowledge graph, consider using this pseudo-code:
function unlock {
DELETE { ?service kees:isLockedBy ?anything }
WHERE { ?service a kees:KnowledgeGraph; kees:isLockedBy ?anything }
}
function lock {
local UNIQUE_URI=${1:-"urn:uuid:$(date +%s%N)$(echo $RANDOM)"}
while : ; do
INSERT { ?service kees:isLockedBy <$UNIQUE_URI> }
WHERE { FILTER ! EXISTS { ?service a kees:KnowledgeGraph; kees:isLockedBy [] } }
if ASK { ?service a kees:KnowledgeGraph; kees:isLockedBy <$UNIQUE_URI>}; then
break
else
sleep 10
fi
done
}
LOCKID=$(lock)
trap unlock EXIT # ensure lock is removed also on script exit
... do your jobs
unlock
trap '' EXIT
Be sure to delete lock even in case of error or script exit
Example of ah hypothetical dump of a KEES compliant Knowledge Graph
@base <http://www.example/sparql/> .
@prefix dct: <http://purl.org/dc/terms/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix kees: <http://linkeddata.center/kees/v1#> .
@prefix sd: <http://www.w3.org/ns/sparql-service-description#> .
@prefix : <#>
# default graph
{
[] a kees:KnowledgeGraph ;
sd:endpoint <> ;
sd:feature kees:Status, kees:Locking ;
kees:isLockedBy <urn:kees:kb:isLockedBy> [ a kees:Activity ] ;
dct:created "2023-12-10T01:10:01Z"^^xsd:dateTime ;
kees:ingested "2023-12-10T01:01:11Z"^^xsd:dateTime ;
kees:reasoned "2023-12-10T01:02:21Z"^^xsd:dateTime ;
kees:enriched "2023-12-10T01:03:31Z"^^xsd:dateTime ;
kees:published "2023-12-10T01:04:41Z"^^xsd:dateTime .
}
# An ingested third party data resource
:98dccee27a081f9cd75d15b8af59a3d6 {
[] a kees:ThirdPartyData;
sd:name :98dccee27a081f9cd75d15b8af59a3d61 ;
dct:modified "2023-12-10T01:01:02Z"^^xsd:dateTime ;
dct:source <http:/example.org/resource.ttl> ;
prov:wasGeneratedBy [ a kees:Ingestion ] ;
dqv:hasQualityMeasurement [ dqv:value 0.99 ; dqv:isMeasurementOf kees:trustLevel ] .
}
# An ingested first party data resulting from a void dataset discovery
<http://private.mycompany.com/.well-known/void> {
[] a kees:FirstPartyData;
sd:name <http://private.mycompany.com/.well-known/void> ;
dct:modified "2023-12-10T01:02:02Z"^^xsd:dateTime ;
dct:source <http:/example.org/void.ttl> ;
prov:wasGeneratedBy [ a kees:Ingestion ] ;
dqv:hasQualityMeasurement [ dqv:value 0.75 ; dqv:isMeasurementOf kees:trustLevel ] .
## here the example triple exposed by http:/example.org/void.ttl
<http://private.mycompany.com/.well-known/void> a kees:KnowledgeBaseDescription ;
foaf:primaryTopic <http:/example.org/dataset1#dataset> .
<http://private.mycompany.com/dataset1#dataset>
void:dataDump
<http://private.mycompany.com/dataset/part1.ttl> ,
<http://private.mycompany.com/dataset/part2.ttl> .
}
<http://private.mycompany.com/dataset1#dataset> {
[] a kees:FirstPartyData;
sd:name <http://private.mycompany.com/dataset1#dataset> ;
dct:modified
"2023-12-10T01:04:03Z"^^xsd:dateTime ,
"2023-12-10T01:05:04Z"^^xsd:dateTime ;
prov:wasGeneratedBy [ a kees:Ingestion ] ;
dct:source:
<http://private.mycompany.com/dataset/part1.ttl> ,
<http://private.mycompany.com/dataset/part2.ttl> .
# ... here triples merged from all data dumps
}
#
:5678cee27a081f9cd75d15b8af594321 {
[] a kees:SecondPartyData;
sd:name :5678cee27a081f9cd75d15b8af594321 ;
dct:modified "2023-12-10T05:07:03Z"^^xsd:dateTime
prov:wasGeneratedBy [ a kees:deduction] ;
dct:source:
<http:/example.org/rules/rule1.rq> ,
<http:/example.org/rules/rule2.rq> .
# ... here triples generated by rules applied to the whole knowledge base
}
:123ccee27a081f9cd75d15b8af59a456 {
[] a sd:NamedGraph;
sd:name :123ccee27a081f9cd75d15b8af59a456
dct:modified
"2023-12-10T01:07:03Z"^^xsd:dateTime ,
"2023-12-10T01:08:04Z"^^xsd:dateTime ;
prov:wasGeneratedBy [ a kees:Ingestion ], [ a kees:deduction] ;
dct:source:
<http:/example.org/data/dataset1.ttl> ,
<http:/example.org/rules/rule1.rq> .
# ... here triples merged from all data dumps
}